近日,快手正式发布了新版多模态大模型Keye-VL-2.0-30B-A3B。作为Keye家族最新一代的30B级主力基座,Keye-VL-2.0-30B-A3B率先将DSA(DeepSeek Sparse Attention)机制引入多模态理解场景,成功解锁了256K超长上下文的深度感知,在长视频时序感知上实现了几乎无损的推理能力。
更具里程碑意义的是,这也是Keye系列首次解锁Agent协作机制,在Code、Tool、Search等复杂场景下展现出了扎实的系统级协作与执行潜力。
DSA首次落地多模态,破解长视频理解瓶颈
视频理解的痛点,往往在于超长视觉上下文带来的指数级计算开销与核心信息的稀释。
Keye-VL-2.0-30B-A3B在底层架构上完成了关键跨越——首次在多模态理解场景中成功应用了DSA(DeepSeek Sparse Attention)。通过结合稀疏注意力与极具针对性的特征聚合,模型在处理长达小时级的视频序列时,能够有效进行高噪环境下的信息提纯,精准捕捉关键帧并理清动态规律。
这一技术突破直接体现在模型对长时序任务的理解能力上。无论是TimeLens的细粒度动作锚定,还是在LongVideoBench上的综合长时序解析,Keye-VL-2.0-30B-A3B都展现出了对同级别甚至200B+超大参数开源基座的显著压制力。
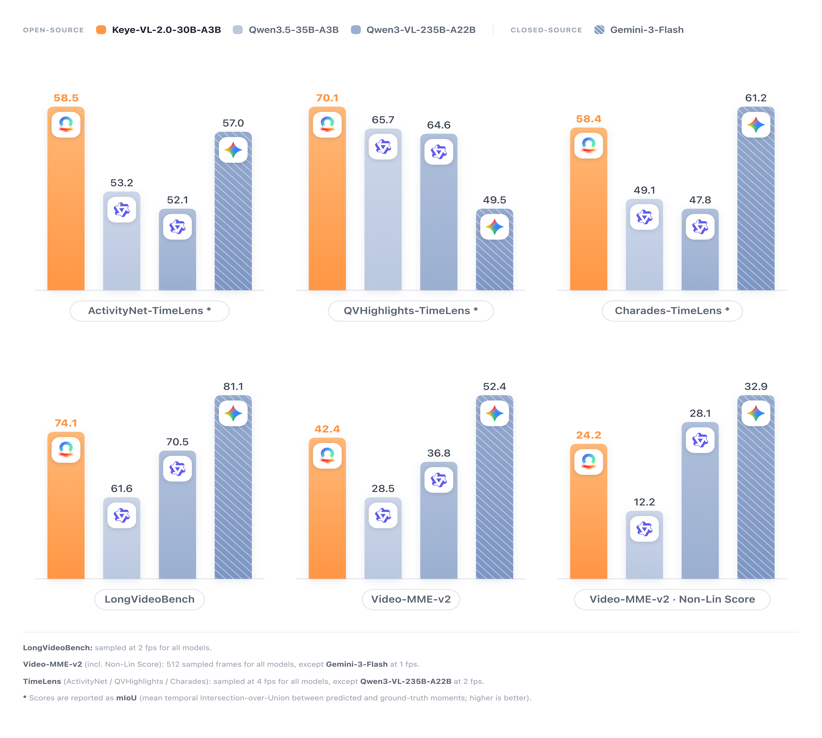
从静态识别迈向深度推理,实现视频理解质变
长视频理解一直是多模态领域最具挑战性的方向之一。
传统视觉大模型通常依赖抽帧与标签化描述完成视频解析,能够识别“出现了什么”,却难以真正理解连续时序中的逻辑关系。因此,当用户输入一段数分钟甚至数十分钟的视频,并要求模型进行总结、规划或决策时,很多模型仍会输出基于字幕与标签拼接的“流水账”。
Keye-VL-2.0-30B-A3B则展现出明显不同的能力路径。在冰岛旅行Vlog测试中,模型不仅识别出天气骤变、极端环境与事故风险等关键视觉信息,还能够结合上下文推演出“需准备保暖装备”“建议优先选择跟团出行”等具备现实决策价值的旅行建议。面对工艺制作视频,模型可输出毫秒级精确时间戳拆解,准确识别复杂工序并完成结构化归纳;在电竞赛事视频中,则能够结合视觉变化、字幕信息和比分演化,还原“绝境翻盘”的叙事逻辑,实现跨模态语义融合分析。
这种能力的关键,在于模型开始建立“时序因果链条”。它不仅理解单帧内容,更能够在长时间跨度的视频流中识别事件之间的关联关系,并基于人类逻辑完成更深层次的规划与判断。
Agent能力首次解锁,打通“感知—规划—执行”闭环
此次发布的另一项关键突破,是Keye系列首次在多模态基座中内建了Agent协作机制。
依托Code Agent、Tool Agent等能力模块,Keye-VL-2.0具备复杂任务拆解、工具调度与多轮执行能力,可在代码解析、API调用、任务规划等场景中实现稳定执行。在复杂业务测试中,面对涉及门店检索、距离测算、商品筛选、订单生成等多线程任务链,模型能够自主完成任务规划、参数调用及容错调整,顺利完成多轮执行闭环。这标志着快手多模态模型正式从“内容理解”迈向“任务执行”,具备更强业务协同潜力。
强化学习与多专家融合,构建可靠推理底座
为了进一步提升复杂推理场景下的稳定性,快手还构建了一套全新的多模态强化学习体系。
其中,Context-RL奖励机制通过混合模态参考信息生成细粒度奖励信号,对数学、代码、多步推理等复杂任务进行事实性约束,降低模型幻觉率。同时,团队引入Accuracy Filtering机制,对训练轨迹进行实时质量筛选,剔除逻辑断层与低质量样本,提升强化学习稳定性。此外,针对多任务学习中的“灾难性遗忘”问题,快手还创新性引入跨模态MOPD(多专家策略蒸馏/合并)技术。
通过动态路由与参数融合,模型在持续增强视频理解与Agent能力的同时,依然能够保持数学推理、STEM与指令遵循等通用能力稳定增长。下图是Keye-VL-2.0-30B-A3B最终定版在全维度基准测试中的“全景成绩单”:
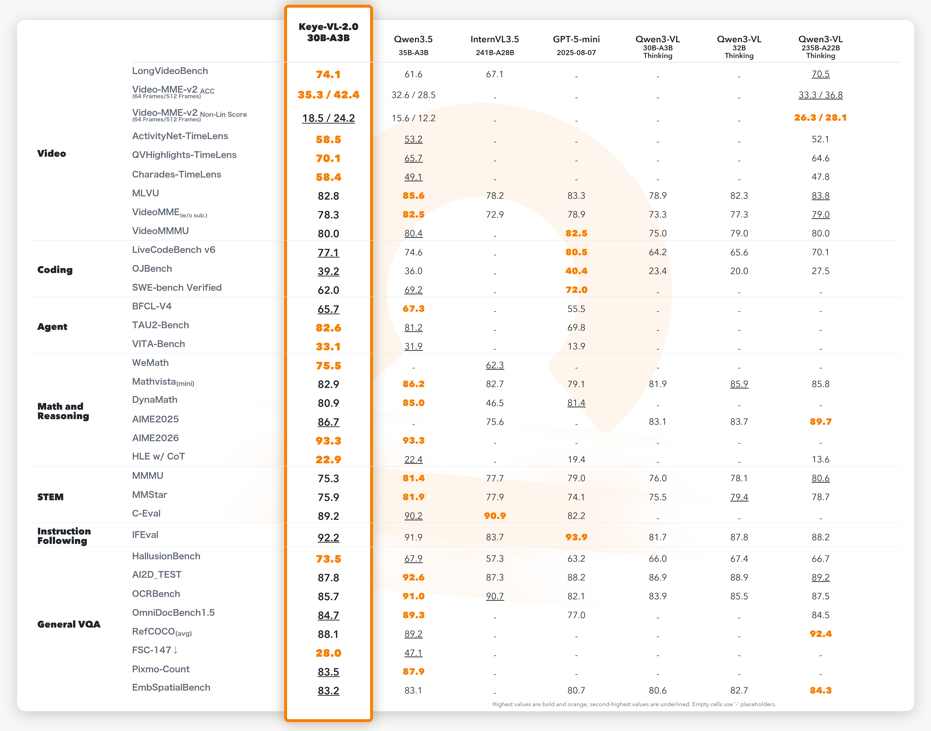
扎根业务场景,推动智能生态全面升级
技术突破的终点不但是榜单成绩,更是业务价值兑现。目前,Keye-VL-2.0已在内容推荐、商业化投放、内容治理等多个内部场景落地应用,通过提升视频语义理解精度,显著增强推荐系统命中率和广告标签抽取效果。与此同时,其Video × Agent能力也将进一步赋能创作者生态,实现视频检索、高光提取、智能剪辑、营销生成等自动化工作流,推动内容生产方式升级。
快手技术团队表示,未来将以将以30B版本的成功经验为跳板,稳步向真正的原生多模态(Native Multimodal)与端到端深度融合挺进,通过一次次扎实的业务验证与版本迭代,持续构筑具有深度的行业技术影响力,沉淀不可替代的核心基建壁垒。















