10月30日,在2025金融街论坛年会金融科技大会上,由北京市西城区人民政府主办、中关村科技园区西城园管委会承办的“2025金融科技应用场景大赛”终评结果在北京正式公布。
腾讯云天御“金融反电诈治理方案”与腾讯云“基于TCS的AI异构算力管理平台”凭借技术创新性与场景落地能力,从全国89家机构提交的280个项目中突围,双双斩获“十佳应用奖”。腾讯混元大模型信贷助手解决方案获得了大赛颁发的“探索实践奖”。腾讯云三大方案分别在金融风控、算力基建及大模型应用三个关键领域展现突出优势,获专家团高度认可。


“2025金融科技应用场景大赛”自2021年启动以来,已经成为金融科技领域极具影响力的赛事平台。本届大赛以“深化科技成果转化,助力五篇大文章落地”为主题,设置数据要素、人工智能(非AIGC方向)、人工智能(AIGC方向)、数字基础设施、数字化转型等7个赛道。“十佳应用奖”由商业银行、科研院所等单位组成的专家团围绕技术架构、创新价值等维度严苛评审,最终评选出10个标杆项目。
天御反电诈
AI大模型构筑平衡
“安全”与“便民”的反诈免疫力

据公安部介绍,电信网络诈骗犯罪已成为数量上升最快的刑事案件类型。在这背后,除诈骗手法多变、技术对抗升级、作案窝点转移境外等原因,更有庞大的信息网络犯罪黑灰产支撑诈骗犯罪活动,通过出租出售电话卡和银行账户、“跑分”洗钱等为诈骗提供帮助,严重危害网络安全、社会稳定和人民安宁。随着黑灰产业链不断升级,对其打击治理难度日益增大。同时,中国人民银行高度重视“资金链”精准治理,指导商业银行、支付机构统筹做好涉诈风险防控和优化服务工作,重点加强技防建设,切实保护好群众资金安全与合法权益。
秉持“科技向善”的使命愿景,腾讯云与金融机构协同对抗诈骗。腾讯云天御应用AI大模型技术,构建行业首个从意图与动机层面预测黑产涉诈风险的反诈风控引擎,形成“扫黑+护白”双模反诈体系;可作用于“事前-开户准入、事中-风险阻断、事后-解控提额”金融账户全生命周期与业务环节,与风控平台、事中规则模型、黑灰名单等机构已有反诈能力“双剑合璧”。目前,这套反诈风控引擎已经经过超百家金融机构实际业务的可靠与有效性验证。
在防范涉诈卡方面,该模型可于涉诈交易发生前0~3个月预测命中超80%的帮信涉诈账户;其中高风险预警在未来3个月内涉诈案发的概率高达10%~30%,超过大多数金融机构事中风险阻断的精准度要求。
在保护受害人方面,该模型可感知超98%诈骗风险类型,预警命中超60%的被骗受害风险;结合渠道实时特征,金融机构可在交易、支付结算前对被骗受害用户采取提醒、核验、劝阻、止损等保护性措施。
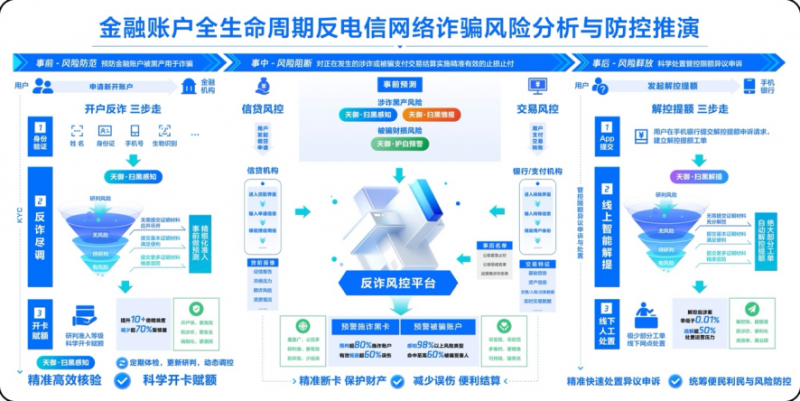
上述能力与金融机构优势互补,可全面提升反诈风险防控的科学性、精准性和有效性。在今年的金融科技应用场景大赛中,大模型技术应用也是焦点之一,AIGC方向项目数量占参赛项目总数的24%,表明生成式人工智能在金融场景中有广阔的应用前景。将大模型技术应用于反诈骗风险防控,也是腾讯云天御反电诈达成上述效果,获得“十佳”应用的创新亮点。
腾讯云天御创新应用AI大模型技术,将过去超15年黑灰产对抗所沉淀的海量风控特征与专家经验,结合大模型在样本之外所积累的世界知识与推理能力;从帮信载体、作案手法、动态趋势等切入,穿透诈骗套路与“跑分”手法的层层迷雾,洞悉纷繁骗术背后的关键意图、动机与本质逻辑;实现更精准预判金融账户潜伏帮信风险,更全面预警交易动账涉诈风险状态。
同时,腾讯云天御基于多模态大模型技术,实现7*24全天候解构海量鲜活的黑灰产威胁情报并归纳总结关键趋势。该模型可以自然语言交互形式,响应业务与运营专家对情报态势的个性化分析需求。自主思考推理核心意图与关切命题,并针对性给出态势型、策略型建议;或结合黑灰产态势与业务现状,提炼生成更全面的分析报告,辅助反诈运营决策。上述探索旨在应用AI大模型技术打破攻防信息差,为反诈科学运营提供多维参考,帮助风控专家持续迭代反诈风控策略。先人一步,跑赢诈骗。
腾讯云天御希望以此创新实践,联合金融机构突破规则风控瓶颈,共筑跨行业多主体联动的自适应防御体系。在达成“防范账户涉诈”与“保护财产安全”双重目标的同时提质增效,有效兼顾展业效率与服务质量,实现统筹“便民利民”与“风险防控”的电信网络诈骗可持续治理。
2023年以来,腾讯云天御与包括国有大行、股份制商业银行、城市商业银行、农村商业银行、非银行类金融机构等在内的众多金融机构并肩反诈。2024年全年,联合超40家金融机构累计对超过6200万被骗受害用户实施劝阻、止损等保护,直接避免或挽回人民群众损失超10亿元,间接保护潜在被骗群众财产超百亿元。充分践行并发扬金融工作的政治性、人民性。
腾讯专有云PaaS平台TCS
提升异构算力管理效益
加速云原生AI构建

AI 技术迅猛发展的今天,算力作为核心生产要素,其管理与调度效率成为企业AI应用落地的关键瓶颈。同时在算力资源分散、供应不稳、需求激增的背景下,企业面临着异构算力资源难以统一管理、资源配置和调度复杂、缺乏智能化监控运维及故障自愈能力、资源利用率低下等挑战。这些问题导致企业运营成本上升,业务创新能力受限。
基于此,腾讯云推出腾讯专有云 PaaS 平台TCS(Tencent Cloud-native Suite, 简称 Tencent TCS)异构算力管理平台,通过提供一站式的异构算力资源整合、调度、运营服务,显著提升资源使用的效率和灵活性,有效控制并优化成本。通过云原生AI技术提升异构算力管理效益,加速云原生AI的构建,助力行业企业在AI时代构建敏捷、高效、安全的算力底座。
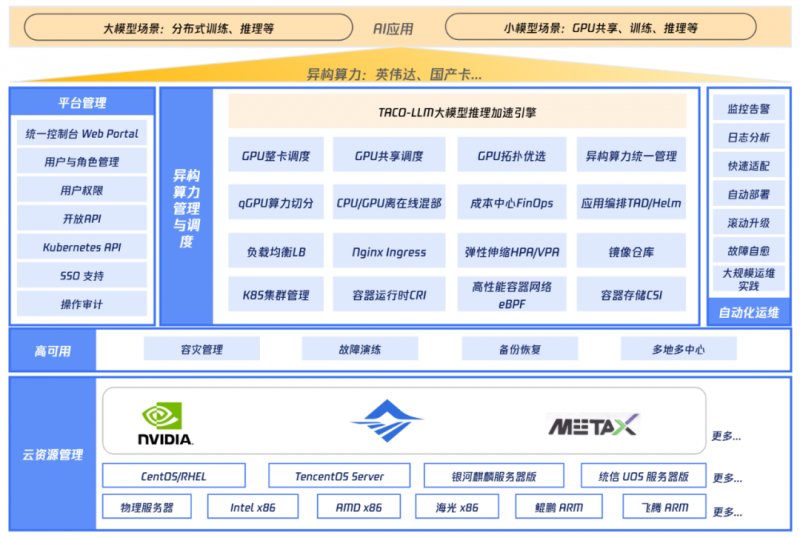
TCS 异构算力管理平台架构总览
在实际应用中,TCS 异构算力管理平台展现出以下四大关键特性:
异构算力统一管理
TCS 通过异构算力统一管理解决方案,实现了对多种类型加速芯片(如CPU、GPU、NPU等)的统一接入和集中管理。该方案借助多集群扩展能力,不仅能够整合多个异构计算集群资源,提供集中式的资源视图和操作入口,打破资源孤岛,还能通过注册集群功能无缝管理异地云外集群,构建真正一体化的算力资源池,从而显著提升资源利用率、简化调度流程并降低运维复杂度。
针对各家加速芯片厂商提供的部署方式各异的问题,腾讯专有云PaaS平台TCS基于TAD(Tencent Application Definition)云原生应用声明式部署规范,提供了标准化的接入接口与适配框架,并实现了快速集成与高效部署,显著降低了适配成本,大幅缩短了部署周期。
异构算力灵活调度
TCS 的异构算力灵活调度方案能够根据应用需求动态分配算力资源,显著提升资源利用率和计算性能。该方案通过智能调度器、DevicePlugin 框架及扩展资源机制,高效管理 GPU、NPU 等第三方加速设备,并支持多样化的调度策略,以满足不同场景的算力需求。
同时,其拓扑感知调度能力可智能分析节点间网络拓扑及节点内部资源互连架构,优化任务性能、加速训练过程,并减少实例间的性能差异,从而确保计算任务的高效执行。
资源利用率提升与成本优化
TCS 通过多项创新技术实现 GPU 资源的高效利用与成本优化。在资源利用方面,采用内核态 GPU 共享技术(qGPU),支持多个容器共享同一张GPU卡,实现算力与显存的精细隔离,其5%算力、1GB显存的细粒度分配能力使资源利用率达到极致,同时确保业务无感知。
同时支持丰富的集群及单卡调度策略,提供Spread(平均分配保证负载稳定均衡)、Binpack(尽量填满保证利用率)、Best Effort(保证最大的吞吐)、Fixed Share(算力最低配置保证)、Burst Share(算力最低保证,允许占用空闲)等多种智能调度模式,可灵活适配不同业务场景需求,既保障负载均衡,又能最大化资源利用率。
特别值得一提的是 TCS 创新的GPU在离线混部调度能力,通过任务的优先级实现抢占调度功能,支撑训推一体业务部署:对高优任务(如在线推理)采用平均分配确保稳定性,对低优任务(如离线训练)则采用填满策略提高利用率,并支持100%在线抢占功能,在保障关键业务的同时最大程度降低资源闲置。
基于腾讯开源项目Crane构建的FinOps成本中心,提供资源可视化、分析及智能优化三大核心能力,旨在提升集群的资源利用率。Crane算法在腾讯内部自研业务中实现了大规模落地,成功部署至数百个容器集群,为企业带来了显著的降本增效效果。目前,TCS FinOps已在多家头部金融及政企客户中成功应用,极大提升了集群的资源使用率。
此外,通过TACO-LLM提供高吞吐、低时延、开放兼容的大模型推理加速引擎,极大提升了推理效率和系统稳定,吞吐最高提升2倍。
智能运维与故障自愈
TCS 的智能运维与故障自愈系统通过自动化管理手段显著提升了异构算力集群的运维效率。该系统具备全面的集群监控能力,可对CPU、GPU、NPU等各类计算资源进行多维度实时监测,覆盖从基础设施到应用负载的各个场景,帮助运维人员快速发现并准确定位运行异常,确保数据中心整体运行的稳定性。在故障处理方面,系统特别针对GPU设备内置了智能检测与自愈机制,能够自动识别硬件故障并触发告警,同时根据业务实际情况智能执行预设的修复方案,大幅降低人工干预需求。
平台还提供统一的运维运营门户,集成监控中心、日志平台、巡检、变更发布、运维工具、安全中心、容灾管理、故障演练等功能模块,有效简化了日常运维流程。这套智能运维解决方案通过自动化扩缩容、智能故障诊断与自愈等创新功能,不仅显著降低了运维人力成本,更确保了异构算力资源的高效稳定运行,为用户提供了更加可靠的算力保障。同时支持多地多中心高可用部署架构,强大的运维及容灾能力帮助上层业务达到金融级高可用能力。
此外,TCS提供基于AI智能体的排障运维助手,通过整合大模型推理能力与TCS领域知识库,实现自动化问题诊断与排障决策。
TCS 创新采用“一云多芯”架构,支持多种CPU、GPU硬件,全面适配多种GPU/NPU。通过异构算力统一管理、多集群扩展、异构算力灵活调度、拓扑感知调度、qGPU内核态共享及离在线混部、FinOps成本中心、GPU故障检测与自愈、智能运维等核心能力,提供一站式的异构算力资源整合、调度、运营服务,显著提升资源使用的效率和灵活性,有效控制并优化成本,为企业业务创新发展提供持续动力。
凭借卓越的技术实力与灵活的管理能力,TCS 目前已在多家金融机构及政企客户中成功落地,为客户AI训练推理业务提供高效支撑。凭借多项可信云权威认证及深度参与行业标准制定,其卓越性能、可靠性及稳定性已获充分验证,有力支持数字金融的创新发展。
混元大模型信贷助手
打通金融领域应用“最后一公里”

2023 年以来,受贷款利率走低、对公信贷市场下沉等影响,金融机构面临项目规模小、数量多的挑战,需要持续加速推进线上化、数字化、智能化转型。腾讯云基于 30 多家金融机构调研,精准把握信贷全流程痛点,历经两年研发打造混元大模型信贷助手,通过场景化后训练和工程开发构建多模型智能体,实现业务准确率、效率与成本的动态平衡。
该方案针对行业存在的非标数据解析难、流程低效、风控滞后、系统割裂、技术断层等问题,构建“信贷智能体”,对多源异构材料进行分类、检测、提取、分析及报告生成,覆盖 95% 以上金融信贷业务场景。
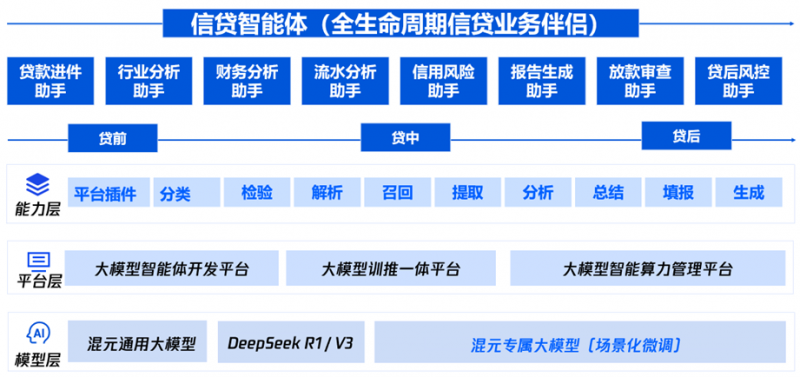
在关键技术层面,方案以混元多模态模型及大语言模型为基础,构建5万+高质量金融信贷数据集,通过场景化后训练让模型掌握业务逻辑与规则;同时强化指令遵循能力,通过专项微调与框架约束推理,结合受限解码、思维链引导等技术,抑制模型幻觉风险,确保输出稳定可靠。
整体方案分为业务输入层、执行层与输出层,打造覆盖贷前、贷中、贷后的通用能力组件,并灵活适配信贷进件、财务分析、报告生成等细分场景。经过持续打磨,方案具备高适配性与稳定性,人工采纳率超93%,输出波动控制在1%以内,可满足不同机构的客制需求,目前正开展大规模POC测试与交付。
实际应用中,该方案成效显著:某泛金融机构引入后,审单准确率达94% 以上,在人力成本不变的情况下大幅提升业务承载能力;某银行对公项目尽调报告生成时间从10天缩短至1天,客户经理工作效率提升10倍。该方案成功打通大模型在金融领域应用的“最后一公里”,为数字金融创新提供范例,将有效延展金融机构员工能力边界,助推普惠金融高质量发展,展现出广阔的业务应用前景。















